For a while, I struggled with the right name for this article. I haven’t put up a blog post in months. But I’ve been writing. I’m always writing. I’ve been locked in, doing research, engineering, building communities, working with startups. It’s been quite the journey.
Last year, I left Moniepoint after a decade-long career to focus on something that might sound abstract at first: building infrastructure for a world where humans get paid for what they know.
What kind of infrastructure you might ask?
Most days, I’m either reading white papers or churning out code. It’s easier to test ideas now that coding agents have become very proficient. There’s been a lot of learning.
So here’s what I keep coming back to:
In a world that is automating very fast, the value of routine knowledge work will keep declining. When large portions of cognitive labor are automated, humans become easier to replace and easier to exploit. Jobs can become displaced, livelihoods can become less stable, and economic gains can concentrate in the hands of those who control the systems.
Without new economic coordination and compensation models, this dynamic risks extending the very wealth inequalities that already define the current digital economy.
So we’ll ask the questions: how do knowledge workers survive automation? What’s the difference between being replaced by AI and being paid by AI?

The Broken Contract
Models trained on the open web have broken the economic contract of the internet.
Before LLMs, the gateway to information was search engines. You got ten blue links. Websites got traffic. Everyone could sell ads or services to the people who landed there. It wasn’t perfect, but it was a loop that sustained a lot of creators.
Generative models have upended this. They increasingly replace the need to visit the source of the information.
And so, the result is a structural mismatch: value flows upstream to those who train and deploy models, while creators are left outside the feedback loop that once justified openness.
Today, platforms capture user data within their systems. Every tweet, post, upload, like, comment creates free training data, which platforms use to build intelligent models. Users get nice UX, but very little of the economic upside. Even when platforms try to compensate contributors, compensation is discretionary, not obligatory.
Sure, platforms have created valuable services. But up until recently, with AI threatening jobs, people didn’t really care that they were giving away their data for free.
Now we might have to start caring.
Take a look at the news of Tailwind Labs. The company was forced to lay off 70% of its engineering team despite hitting a record 75 million monthly downloads. While the web framework powers giants like NASA and GitHub, its revenue has plummeted by 80%.
How can a tool be more popular than ever while its business model collapses?
In the pre-AI era, a developer stuck on a layout problem would visit the official Tailwind docs. While searching for a fix, they’d see an ad for Tailwind Plus, and a reliable percentage would convert into paying customers. This was the lifeblood of the business.
Today, that same developer simply asks Claude or Copilot. The AI provides the exact code instantly, the feature ships, and the developer never visits the website.
- The Result: Website traffic has dropped since the advent of LLMs, even as actual Tailwind usage tripled.
- The Consequence: Without those eyeballs, there is no discovery, no sales, and no way to fund the team.
And this isn’t just a Tailwind problem; this is happening to millions of websites across the internet; it’s a warning for the entire ecosystem. When work is absorbed into training data and served back to users without attribution or compensation, the very people building the future can no longer afford to live in it.
The Data Value Capture Problem
The Data Value Capture problem is the mismatch between who creates the raw material (people generating data through activity, content, choices, and feedback) and who captures most of the value (platforms that collect, aggregate, model, and monetize).
But this problem is also an opportunity.
Because access to data determines what a system can even begin to reason about. Without data, no matter how sophisticated the intelligence, blind spots will remain. You can’t reason about what you cannot observe or what you don’t know. This is why, even as AI systems grow more capable, data will remain foundational to intelligence.
And even with continued advancements in synthetic data, we still need human-generated content. Human data carries context, intent, judgment, and lived experience; signals that are difficult to fully simulate. Human data remains the most reliable source for grounding intelligent systems in the real world.
But, if humans are not rewarded for the data they can reliably provide, they won’t provide said data at the scale or quality needed. This is already starting to play out.
What Happens When AI Runs Out of Human Content to Learn From?
Human-Computer Symbiosis
Referencing Joseph Licklider’s white paper Man-Computer Symbiosis. As early as 1960, he envisioned a symbiotic relationship forming between humans and computers due to their complementary strengths.
This symbiosis is happening before our very eyes. Witness how tethered we are to our machines: phones, tablets, laptops, etc. Most of us can’t do without our phones, and we can’t work without our computers.
We have a tight coupling where humans and computers each do what they’re best at. Humans create intent, set goals, hypotheses, and criteria. Computers are better at remembering things and doing the routine work that prepares the way for insight and decision.
If we treat human inputs as first-class contributions, we can build systems where:
- Humans provide context and judgment: domain constraints, edge cases, ethical boundaries, etc
- Machines do the heavy lifting: search, drafting, synthesis, simulation, optimization, execution
- Humans evaluate and steer: verifying, ranking, approving, correcting, setting criteria
- Value flow within the system incentivizes and rewards contributors

The Building Blocks
Teams across the world are working on pieces of this puzzle. No one has all the answers, but different approaches are emerging.
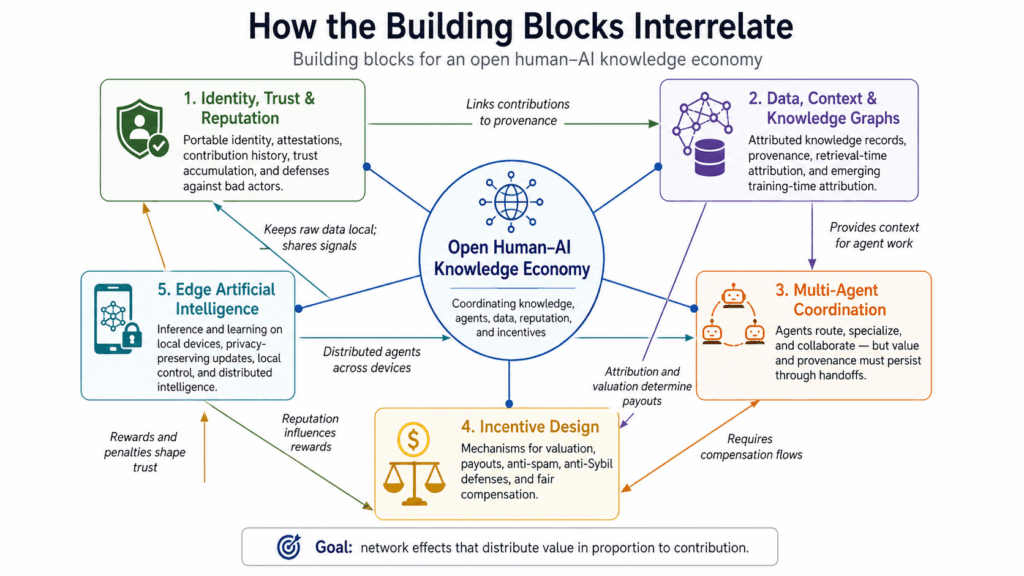
Identity, Trust, and Reputation
We need ways for people and organizations to own digital identity, link contributions to that identity, and build trust over time.
This involves Decentralized Identifiers (DIDs) that are portable across networks. Attestations where people and systems vouch for each other. History and context: what has this identity actually done?
Bad actors can be detected, penalized, or removed. Good actors accumulate a reputation that makes their contributions more valuable.
Data, Context, and Knowledge Graphs with Attribution
AI as an automation layer built over data records and knowledge graphs, where contributions trace back to real people and communities.
There are two distinct opportunities here:
Retrieval-time attribution, which is tractable today. When your documented knowledge gets used to solve a task, provenance is straightforward. The system knows which chunks it used and who authored them.
Then there’s Training-time attribution, which is harder. How much did your specific contribution improve model capability? This is an open research problem, with different ideas currently being pursued.
Attribution is only half the problem. You also need valuation; how much was that contribution worth? Are we going Usage-based or Outcome-based? Or some blend? The mechanism design matters as much as the technical tractability.
Multi-Agent Coordination
The dominant framing of multi-agent systems focuses on efficiency: agents that route tasks, specialize in skills, and coordinate to solve problems faster.
The harder question is: when a network of agents collaboratively produces value, how does compensation flow back to the humans whose knowledge, data, and judgment made that production possible?
Even though we are seeing protocols emerging to support these systems, current infrastructure efforts remain largely agnostic on the question.
x402 is a HTTP-compliant, chain-agnostic protocol that unlocks payments on the internet for APIs, content, and AI agents. It was released in May 2025 and has revealed a potential to unlock more economic activity on the internet. But it’s more of plumbing.
There are also projects like NANDA, which originated at MIT. The NANDA project is building infrastructure around the agentic web, with problem spaces like agent discovery, reputation, and coordination.
Recently, an Ethereum Improvement Proposal (EIP) was put forth for Trustless Agents. ERC-8004. A standard for discovering agents and establishing trust through reputation and validation.
These are all necessary primitives. But primitives don’t determine outcomes. HTTP didn’t dictate whether the web would concentrate into five platforms or remain decentralized. The protocols emerging now will similarly underdetermine the structure that forms on top of them.
The opportunity, then, is to build coordination mechanisms that treat compensation as a first-class concern, not an afterthought.
This means provenance tracking that persists through agent handoffs, payment flows that reach upstream contributors, and even reputation systems that create leverage for knowledge workers rather than just legibility for platforms.
Interoperability and open standards matter, but only instrumentally. Because the goal isn’t network effects for their own sake, but network effects that distribute value in proportion to contribution.
Edge Artificial Intelligence
Edge intelligence shifts training and inference from centralized cloud infrastructure to the devices where data originates: phones, laptops, embedded sensors, and local servers. We’re doing this not just for latency optimization, but also as an architectural pattern that keeps raw data under local control while still participating in broader learning and coordination networks. The device interprets multimodal input, makes autonomous decisions, and selectively shares compressed signals, gradients, or policy updates rather than streaming sensitive information to a central authority.
The technical landscape is maturing but still uneven. On-device inference is increasingly viable thanks to model compression techniques (quantization, distillation, pruning) and dedicated ML accelerators in consumer hardware.
But the harder problems are systemic: maintaining model coherence when nodes train on non-local data, handling unreliable connectivity without creating stale or divergent behavior, and designing update protocols that don’t leak private information through gradient inspection. Federated learning addresses some of this, but production deployments remain concentrated in well-resourced organizations.
The long-term significance is less about performance than about power distribution. Edge-native architectures make it structurally harder to consolidate control over AI capabilities. The intelligence diffuses, the data never centralizes, and users retain meaningful agency over what their devices learn and share. That’s a prerequisite for any model where participants aren’t just data sources for someone else’s model.
Incentive Design
Building open, multi-agent systems means doing game theory and mechanism design whether you frame it that way or not. Because the challenges are unavoidable: Spam, Free-riding, Sybil attacks, to name a few.
How do you prevent the system from devolving into extraction, where sophisticated participants game the rules at the expense of genuine contributors? These are the core architecture decisions that determine whether a network creates value or just redistributes it toward those who understand the rules best.
The standard toolkit includes reputation scores, token staking, and performance-based payouts, but each comes with known failure modes.
Reputation systems face cold-start problems and can be gamed through collusion or purchased accounts.
Staking requirements create capital barriers that skew participation towards those who already have the resources.
Performance metrics trigger Goodhart’s law: once a measure becomes a target, participants optimize for the metric rather than the underlying goal.
It’s easy to pay someone for a physical unit of work, like renting a server or storing a file. It’s much harder to pay someone for a ‘vibe shift’ or a moment of brilliance. Most crypto-marketplaces fail here because they treat human knowledge like a commodity. They can measure how much electricity a computer uses, but they can’t easily measure how one expert’s niche insight made an entire AI model smarter. We need a system that rewards the ‘glue’: the collaborative, messy human expertise that doesn’t fit into a simple metric.
Several projects are exploring different approaches to these tradeoffs. Bittensor uses a competitive validation model where miners are ranked by subnet-specific performance. Prime-Intellect is focused on coordinating distributed training for open foundation models. Intuition is building attestation primitives for identity and reputation claims. The ASI Alliance (SingularityNET, Fetch.ai, Ocean Protocol) is attempting interoperability across specialized AI networks.
I’ve been keeping a close eye on Bittensor in particular, because the network has managed to mirror Bitcoin’s tokenomics while generalizing the tokenomics from energy capture to intelligence capture and utility.
Currently, I am contributing to open source projects while supporting ecosystems that explore and champion the best ideas. I formed a discord community. And we have a playground on github for exploring our ideas. It’s not much, but it’s honest work 😇.

Towards Utopia
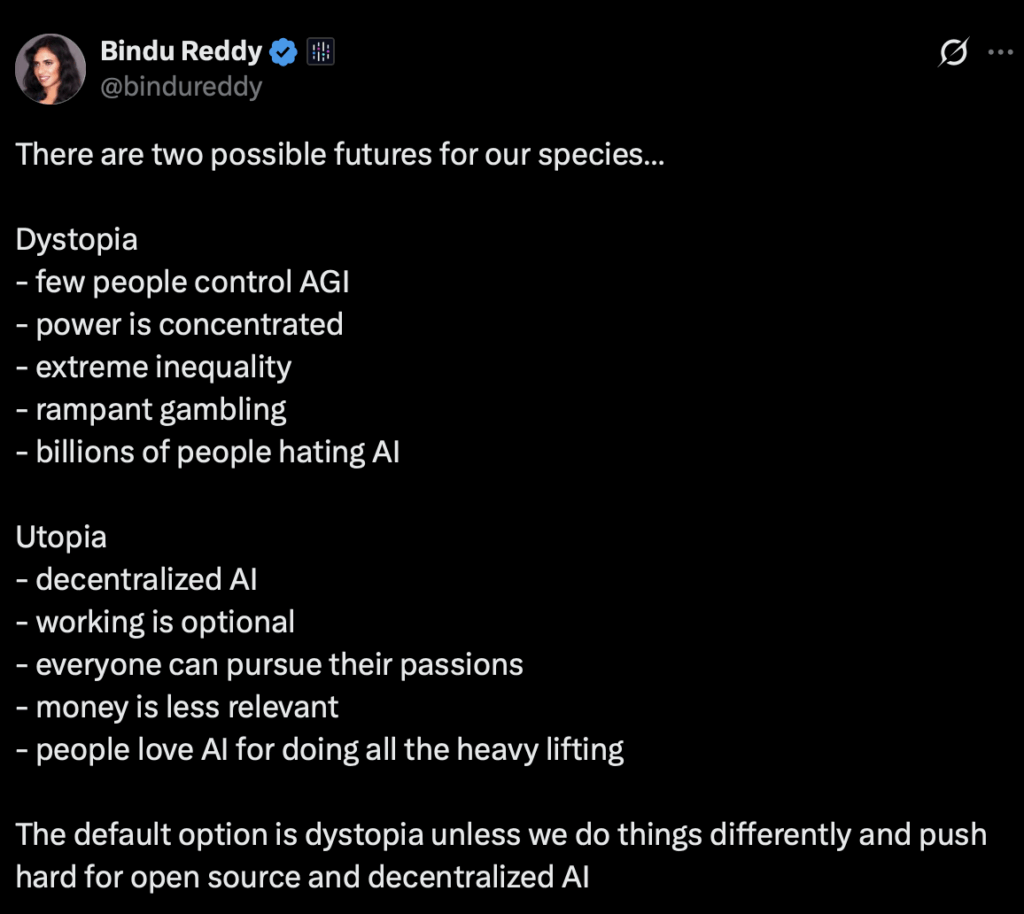
This is how I see it as well.
We are flirting with two equilibria over the next few decades.
Dystopia is the default because it’s the easier path. The current internet’s structure rewards platforms that capture network effects; more users attract more users, early advantages compound, and value concentrates at the top. This is the natural order of digital markets.
Utopia, the alternative, requires deliberate work. Open protocols, public infrastructure, and coordination mechanisms that make decentralized systems competitive with centralized ones in terms of speed and usability. What kind of public infrastructure? Open protocols, payment rails, data commons; infrastructure that’s expensive to build, owned by no one, while underwriting trillions in value built on top of it.
Right now, AI training is extractive: data flows in, capabilities flow out, contributors get little to nothing. We rely on the benevolence of big platforms. This happens because training data is a one-time acquisition. Once it’s scraped, the leverage disappears.
Even more interesting when the contribution becomes continuous rather than historical. If AI systems need ongoing human judgment, verification, and domain expertise, not just static datasets, then contributors have some leverage.
The real question is: can we build a system where doing the right thing, contributing high-quality work, is also the most rewarding thing to do?
Owning your data sounds good in theory, but in reality, we trade privacy for convenience every single day. The real fix is in changing how the money flows. We need a system that pays you the moment you provide value, rather than one that lets platforms scrape your brain for free today only to sell the results back to you tomorrow.
Even More Problems 😩
Indeed, there are real risks and even harder problems. A few I think about:
Switching costs. People and organizations are comfortable with systems that “just work,” even if they’re extractive. Better technology is not always enough to make people switch. The friction of migration is real: learning new tools, transferring data, rebuilding workflows. And there’s a deeper psychological barrier: most people don’t feel the extraction happening. Cost is diffuse, spread across millions of users, invisible in any single interaction. We’ll need to build culture and help people understand why this matters, because it protects their intellectual property and their livelihoods. But understanding alone isn’t enough. The alternative has to be better in ways people can feel immediately, not just in principle.
Critical mass. A network like this needs enough participants, data, and compute to be useful. Getting there is hard. We have a cold start problem. You need contributors to attract users, and users to attract contributors. Network effects work against you until they work for you. The path forward probably isn’t trying to compete everywhere at once. It’s finding specific communities, researchers in a niche domain, professionals with specialized expertise, where the value proposition is sharp enough to overcome the initial emptiness. Then grow from there.
Regulation and compliance. We have to navigate laws around data, finance, and AI while staying true to user sovereignty. This is harder than it sounds. GDPR creates obligations around data handling that don’t map cleanly onto decentralized architectures. If there are tokens or payments involved, financial regulations kick in, different in every jurisdiction. AI governance frameworks are still emerging and vary widely. So, the tension is real: user sovereignty often means users control their data, but compliance often means someone has to be accountable. Threading that needle requires careful legal and technical design.
Storage, sync, and scale. Keeping petabytes of data in sync in a distributed way, cheaply and reliably, is non-trivial. Centralized systems have had decades to optimize for this. They’ve built massive infrastructure, squeezed out inefficiencies, and amortized costs across billions of users. Distributed alternatives face a harder problem: coordination overhead, consistency guarantees, and the fundamental tradeoffs between availability and partition tolerance. It’s solvable, but the solutions aren’t free. We need approaches that are economically viable at scale, not just technically possible in a demo.
Security and adversarial behavior. Any open network attracts bad actors. The more valuable the network becomes, the more sophisticated the attacks. Sybil attacks, spam, coordinated manipulation, and data poisoning. We need strong defenses without turning the system into a closed club. That’s a tension: openness enables permissionless participation, but permissionless participation enables abuse. Hence, the design challenge is creating accountability mechanisms that don’t collapse back into centralized gatekeeping.
Co-option by large players. If we’re not careful, the same actors who dominate today can simply sit on top of new infrastructure and extract all the value again. This is the embrace-extend-extinguish playbook. Build compatible interfaces, attract users to a “better” implementation, then gradually introduce proprietary features that lock people in. Open protocols don’t guarantee open outcomes. It’s not about whether the technology is decentralized, but whether the power dynamics around it resist re-concentration.
These are some of the problems I think about. I’m sure there are more. None of them is unsolvable, but none of them are solved by good intentions alone.
So, Where We Are?
Right now, we’re still very early. I spend most of my time coding, doing research, mentoring young engineers, and building communities. We started Flow Research as a community of people who believe in the mission. Today, we provide technology solutions for a few organizations, like Accelerate Africa who are doing great work to support founders building and facing tough conditions in Africa.
We’re experimenting with open standards for identity, knowledge bases, and AI agents, with mechanisms that enable sustainability. We’re diving into the foundations of distributed peer-to-peer computing, federated learning, multi-agent systems, neural and cognitive architectures, and more.
A lot will change. Some ideas will turn out to be wrong.
But the questions feel essential, and the journey feels worthwhile.
Get Involved
If this direction resonates with you:
Follow the projects. We will share updates about our projects, experiments, and learnings on our discord and other social channels and through our open-source repos.
Contribute. If you’re a builder, researcher, designer, or just a curious tinkerer, there’s space to help shape the protocols, tools, and experiences.
Challenge the ideas. If you see flaws or blind spots, we want to hear them. Pragmatism wins in the end.
Wrapping Up
I don’t know exactly how this will all play out. I don’t know what will happen in the next couple of years. I do know that the way we handle intelligence and incentives over the next decade will define a lot about our future.
We have to make an attempt to push that future in a more open, fair, and human direction.
Let’s see if we can pull it off.