In today’s rapidly evolving software development landscape, staying competitive and keeping up with user demands is more critical than ever. Microservices offer a flexible, scalable, and resilient solution to building complex applications. But before we dive into the world of Microservices, let’s first take a closer look at Monolithic Architecture.
Monolithic Architecture is a straightforward and efficient approach to managing application code. By consolidating all the code into a single executable program, it simplifies the building, testing, and deployment processes. However, as the application grows in size and complexity, this simplicity can become a disadvantage. With a Monolithic Architecture, implementing any change or update to the system necessitates redeploying the entire application, which can result in downtime and disruption to the entire system. Although, to mitigate downtime, various approaches, such as Canary deployments, can be utilized.
In Microservices Architecture, which is a framework we use heavily at Moniepoint, the approach is somewhat different. The application is broken down into smaller, loosely-coupled services that communicate with each other over well-defined APIs. Each service can be developed, tested, and deployed independently, providing greater agility. With Microservices, developers can focus on building and maintaining smaller, more manageable components, reducing the complexity of the system as a whole.
> Benefits of Monolithic architecture over Microservices
- Simplicity
- Easier to maintain
- Easier to deploy
> Benefits of Microservice architecture over Monolith
- Ability to scale different parts of the system independently.
- Ability to deploy different parts of the system independently.
- Higher Resilience against failures, since issues are more isolated.

While Microservices are often considered the ideal choice for developing scalable and resilient systems, the tried and tested Monolith cannot be overlooked. However, in many cases, a well-structured Monolith can offer the same level of code cleanliness and maintainability as Microservices, without the added complexity. This well-structured Monolith is often referred to as a Modular Monolith or Modulith. With a Modular Monolith, you can enjoy the benefits of a Monolith and the flexibility of a modular architecture while maintaining code quality and maintainability. Each module is designed to be isolated from the others, resulting in decoupled modules that are easier to maintain.
So, whether you’re considering using a Monolith or Microservices for your application, there’s no one-size-fits-all solution. It all comes down to your specific needs, requirements, and goals. Generally, it’s best to start with a Monolith, and then gradually evolve your architecture as you need to.
A Closer Look at Microservices.
Think about Microservices as a system comprising multiple services where each service is self-contained, and services communicate with each other via APIs or some well-defined mechanism. API, short for Application Program Interface is a medium over which you can invoke functionality within a service.
Let’s imagine we’re developing a Hospital Management System (HMS) that can efficiently store and retrieve patient health records via an API. This system will save critical patient information, attending physician details, diagnoses, and other relevant data in a database, making it easily accessible to authorized users. But that’s not all – the system is designed to provide additional APIs that allow for the extraction of valuable insights or analyses on existing records.
To build such a powerful and adaptable system, we need to apply one of the fundamental principles of the Microservice paradigm – Decomposition. It’s like breaking down a large puzzle into smaller, more manageable pieces. By doing this, we create a set of smaller puzzles that are easier to solve, and this allows us to build a system that is modular and flexible.
Decomposition in technical terms stems from decomposition in business terms. Decomposition of the business domain. Your business domain is the totality of all context that pertains to your business. What you want is to properly decompose your business domain into its sub-domains. This means a careful organization of functionality within your architecture into individual services, with each service designed to address a specific concern within the business domain (or by extension, the technical domain).
For example, in our Hospital Management System scenario, if I need to send emails to my users, I could have an email service. If I need to send sms to my users, I could have an sms service. If I need to keep track of orders placed by users, I could have an order service. You get the idea.
Note: A monolith will probably suffice for our Hospital Management System, but for the sake of our understanding, let’s assume we are engineering a Microservice setup.
So how can we decompose a system into microservices?
We could be working on breaking apart a monolith into individual services or building a microservice setup from scratch. Either way, it’s great to have a formal approach to decomposition. Personally, I would recommend the following steps:
Isolate and group functionality
First, identify the different functionalities that will need to be supported by your system. At a high level, you can start to see these functionalities if your business domain has been well-defined. Functionalities that are related in some way should be grouped together. In grouping these functionalities, you may realize that some of these groups can be handled by 3rd party libraries or existing solutions. In this case, no need to build in-house since existing solutions can be leveraged.
Using the example of our HMS, some functionalities we may discover:
- As an Admin, I should be able to log into HMS
- As an Admin, I should be able to onboard a new Doctor on the platform
- As an Admin, I should be able to view all Doctors and Patients on the system
- As an Admin, I should be able to view the details of a Doctor or Patient on the system
- As a Doctor, I should be able to log into HMS
- As a Doctor, I should be able to schedule appointments with a Patient
- As a Doctor, I should be able to view my scheduled appointments
- As a Doctor, I should be able to view a Patient’s Health History
- As a Doctor, I should be able to add a new record to a Patient’s Health History
- As a Doctor, I should be able to add a Prescription to a Patient’s record
- As a Patient, I should be able to sign-up for HMS
- As a Patient, I should be able to log into HMS
- As a Patient, I should be able to schedule an appointment with a Doctor
- As a Patient, I should be able to view my scheduled appointments
- As a Patient, I should be able to view my Health History
- As a Patient, I should be able to place an order for medication using a Doctor’s prescription
This is by no means an exhaustive list, but from the items listed above, you can imagine our system will need to serve 3 different entities: Patients, Doctors, and Admins. An entity is anything of interest in our domain that has an identity and some well-known attributes. We can identify 3 functionality groups: one for each identified entity. This could mean assigning a service for each group: patient-service, doctor-service, admin-service. This is a somewhat simplistic approach, but it might suffice for our use case.
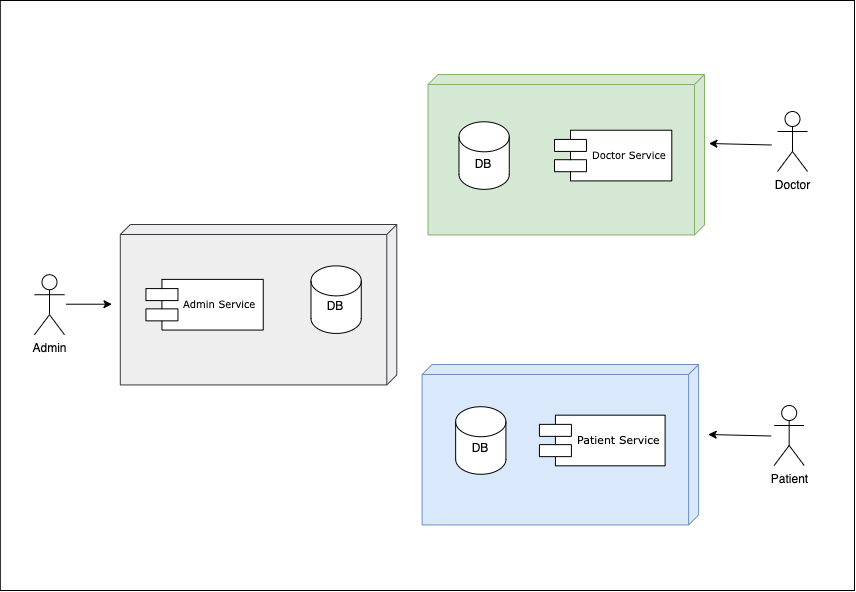
This arrangement yields some benefits, even in terms of security. Say we want to implement some network-level security for the different services, our patient-service can be public-facing and available to anybody over the internet; our doctor-service can be deployed behind a VPN (Virtual Private Network) and made only available to users (doctors) within our private network, our admin service can employ even tighter restriction and be made available to IPs in a CIDR range.
Functionalities could also be grouped by other means, including business function. For example, in the list drawn up above, some functionalities revolve around appointments; Doctors and Patients should be able to schedule and view appointments. We could have an appointments-service which allows users to schedule and manage their appointments.
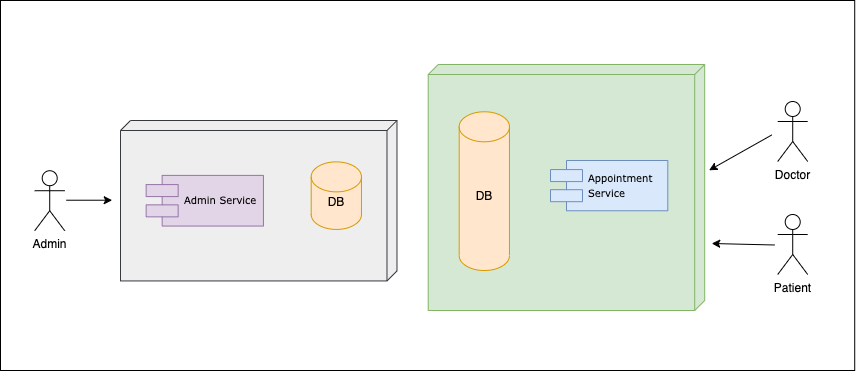
Using this approach might imply we’ll need to create a service to address each business function within our domain.
Identify Subdomain Boundaries.
A sub-domain is a logical boundary that separates the different parts of the system according to the business functions and responsibilities. The boundary comprises the classes, entities, and components that will exist within each service, including the schema and data that will constitute the database for that service. Establishing boundaries also provides a footing on which to deliberate on the APIs that will be exposed by each service.
What kind of Database? Shared Database or Database per Microservice?
When it comes to data persistence in our architecture, there are a few crucial questions we need to ask ourselves. First and foremost, we must consider the type of database that would best suit our needs. Is a Relational Database the way to go, or would a Graph database be better suited for handling our inherently graphical data? Additionally, we need to determine whether we want a Shared Database or a separate Database for each Microservice. These are all essential considerations that will help us ensure we have the best possible database infrastructure to support our goals.
In a Shared Database pattern, you have multiple services connected to a single Datasource. All reads and writes by the different services happen against the same database.

This has some benefits but also some drawbacks.
> Benefits:
- Simpler to operate.
- Easier to enforce data consistency.
> Drawbacks:
- May open up the services to unnecessary coupling.
- Greater probability of service interference at the database level due to row-level or table-level locks.
- Scaling becomes trickier. Scaling a service could impact your database and by extension other services.
- Greater security risk as all services have access to the same data.
In a Database per Service pattern, you have each service connected to its own Datasource. This creates greater decoupling of services since each service handles its data independently without interfering with other services’ data. Services communicate only via APIs.
Database per Service pattern has several benefits over the Shared Database.
> Benefits.
- Better Scalability
- Fault Tolerance and Isolation
- Flexibility
- Services are more independently deployable.
> Drawbacks:
- Data Consistency becomes more challenging
- More expensive to run and maintain

In a hybrid approach, Database per Service Group can equally suffice. Where you can have a group of related services sharing the same database. This approach can allow you to reap the benefits of a shared database and database per service. Particularly in cases where it makes sense for the services to share the same Datasource.

Identify Cross-cutting concerns
Cross-cutting concerns affect multiple modules or layers within a system’s architecture. Examples of cross-cutting concerns include security, logging, transaction management, and caching. Security is probably the first concern we might need to address. Our users (regardless of their role) need to be able to log into the platform.
When a user logs in, they should only be able to carry out those actions they are allowed to do. A patient should not be able to onboard a new Doctor; because that action is restricted to Admins. This security concern cuts across our entire system. For every action that can be invoked by a user, we want to ensure that the user is authorized to carry out such action. We can delegate Authentication and Authorisation to an Auth server, which may exist as a stand-alone service within our infrastructure or a third-party server.
Answer the question: library or service?
Service implies a separate process that is independently deployable (possibly) with its data storage and exposed API(s). A library on the other hand implies a reusable collection of code that can be imported into other services. A library is not a stand-alone service. When you group functionality, or identify cross-cutting concerns, it is important to answer the question: should this function group be handled by a library or a service?
Logging as a cross-cutting concern can be conveniently handled by a library; Caching can be implemented by a library, or if we’re using a tool like Redis as our cache, that would mean accounting for a Redis instance within our infrastructure. Trade-offs will need to be thought through and discussed by the engineering team.
Identify the medium for inter-service communication
How will our services communicate: Soap, REST, GraphQL, gRPC, WebSockets, etc? How do we plan to support Synchronous and Asynchronous IO within our infrastructure? Are we using Messaging tools like RabbitMQ and Kafka for asynchronous messaging? How do we plan to support ‘Fire and forget’ or ‘Guaranteed Delivery’ patterns for our operations? Are we installing an API Gateway? Are we employing Service Discovery or do we want services to explicitly know about each other? Some of these questions can be answered at this point, and some of them can be deferred.
When building microservices, there are many variables to consider. However, this is where software architecture shines – it involves making informed decisions while balancing different tradeoffs.
Keep in mind that good software architecture requires us to defer important decisions until we have a better understanding of the context. In the meantime, we can reason from a higher level of abstraction and use available information to guide our decision-making process.
Successful architecture requires architects to have a thorough understanding of the problem space and its constraints. However, it is important to remain flexible and open-minded in our approach. By prioritizing adaptability and flexibility, we can overcome any obstacles that arise and create something truly remarkable. Let’s approach this journey with confidence and a willingness to embrace the unknown.
In my next note, I’ll touch on distributed systems concepts like synchronous/asynchronous IO, distributed transactions, messaging, event sourcing, SAGA, and much more. Ciao.