In my previous post, I discussed the Microservices architecture and the process of decomposing a business domain into constituent services. Today, we’re going a step further by diving deeper into this paradigm and exploring additional concepts that are essential for the successful application of microservices.
At the core of any engineered system lies its primary purpose: to serve the business by delivering value to users, often in exchange for revenue. To achieve this, it is crucial to process user requests efficiently and effectively.
In the realm of distributed systems, request processing can be either synchronous or asynchronous. Synchronous processing follows a sequential order, with each task completed before moving on to the next. While this approach simplifies software development, it can sometimes lead to underutilization of computing resources, particularly when there are blocking IO calls to external services. What do we mean by this?
Let us imagine a use case in our Hospital Management System (HMS): a patient wishes to log a request to schedule an appointment with a physician. Here’s a summarized requirement:
As a patient, I want to request an appointment with a physician, so that I can receive timely medical care and maintain my health.
Acceptance Criteria:
- Users should be able to provide a preferred date for the appointment
- Only active patients are allowed to book appointments online. If the patient’s account is inactive, the user should be shown an error message.
- The system should book patients with a suitable physician on their preferred date or the closest possible date.
- Both patient and doctor should receive email notification of the confirmed appointment.
Say we have an architecture like the one below:
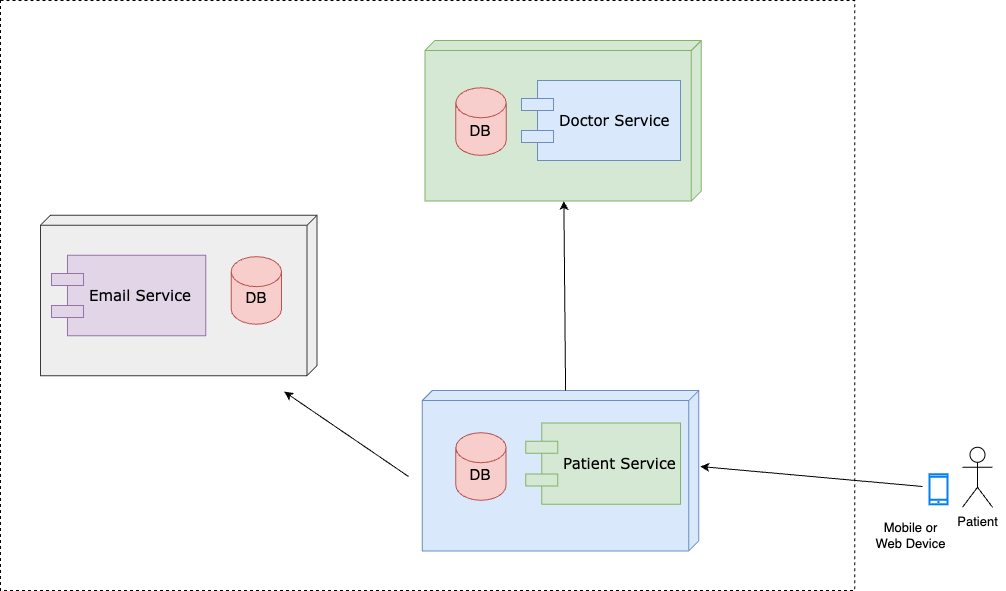
At the time the patient’s request is logged against patient service, patient service has a bunch of things it needs to do. First, it must validate the API request against the data in the database. Is the patient an active patient? Are they eligible to book appointments?
Once the request has been validated, patient-service issues an API call to doctor service which has the record of the available doctors and their appointments. On confirming an appointment, patient-service sends an email to the patient and doctor through email-service; this will involve API call(s) to email-service. If you notice, you’ll see that one API call from the patient’s mobile device to the patient service API has resulted in multiple API calls to other services behind the scenes. All this is ongoing while the user sees a loading spinner on the front-end view.
With synchronous processing, when the user issues a request to schedule an appointment, we have a sequence that looks like this:
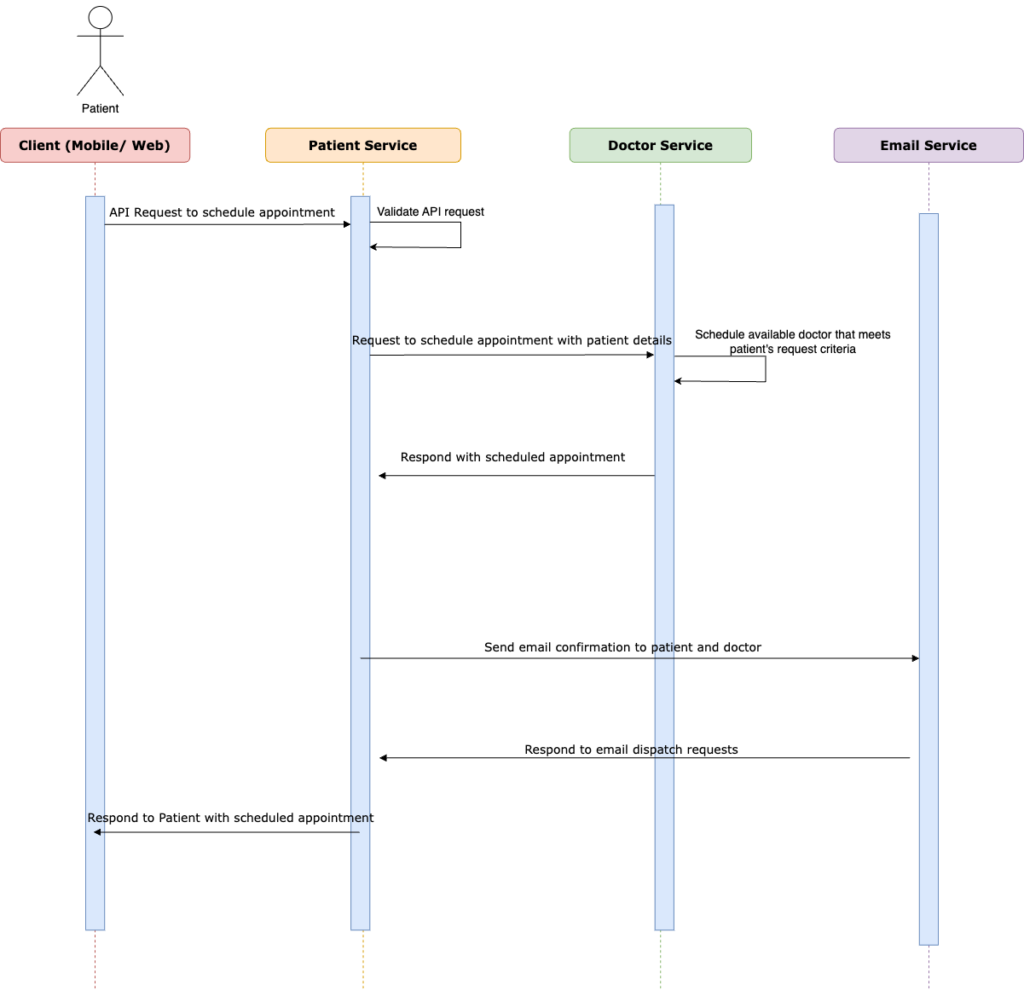
This might not offer the best in terms of User Experience when you think the above sequence is even relatively ‘happy‘. We assume that other services on which patient service is dependent (doctor service and email service) are available at the time the patient logged the request.
Doctor Service and Email Service have become significant bottlenecks in our request processing. In the event that either of these services is unavailable, our entire request processing comes to a grinding halt. Consider the scenario where the email service is down at the time of the user’s request – even if we successfully confirm the appointment on the doctor service, we will not be able to dispatch emails to either the patient or the doctor. This not only leaves our users in the dirt but also prevents us from responding to them since our response is contingent upon a call to the email service, which is currently down. Our poor users are left staring at a loading spinner on the UI while our backend frantically tries to navigate this conundrum.
Ultimately, when everything goes awry, we are left with two less-than-ideal options: either we send a failed response back to the user, or the entire API times out. As it stands, our appointment API on the patient service is not as robust as it could be since we have opted for a synchronous design. This leaves our patient service API vulnerable to downtime in our doctor service or email service, which is far from ideal.
The Asynchronous approach to task processing can often prove to be the more efficient method. Unlike synchronous processing, the system does not wait for a task to finish before moving on to the next one. This approach is particularly useful when dealing with multiple calls to external services. Async programming utilizes callback functions or promises to alert a calling program of a completed task, freeing up the program to proceed with other tasks while waiting for the response. This translates to better use of computing resources, resulting in a much more streamlined execution.
Some APIs should be processed synchronously and some should be asynchronous. Which pattern to use largely depends on the context.
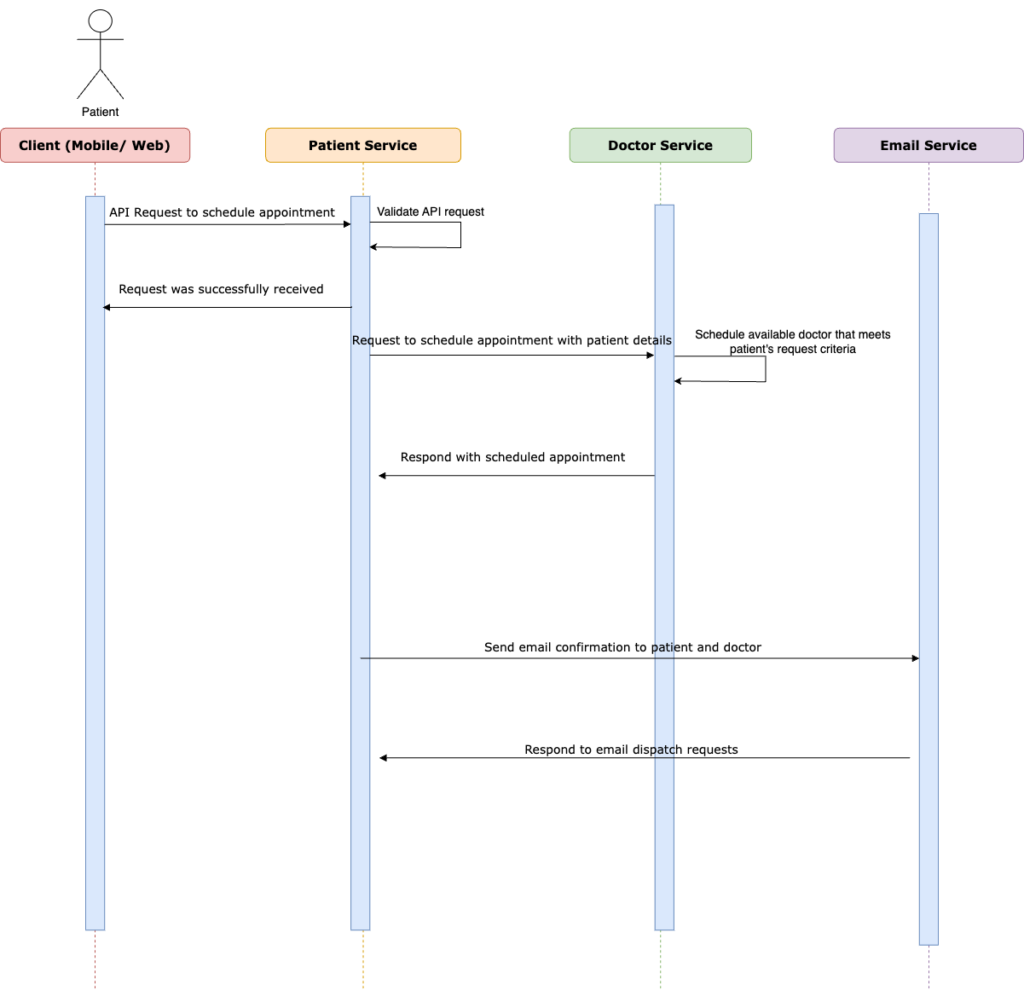
Let’s explore how we can streamline our user request process.
- Once the request arrives at the patient service, we can apply some business logic to ensure the request is valid before we save it in our database.
- From there, we can swiftly notify the user with a reassuring response: “Your request has been received. We will inform you as soon as we book your appointment”. Users can carry on with their day-to-day activities without a second thought.
- With that taken care of, a scheduler can periodically scan the appointment requests that are still in a pending state and attempt to resolve them through API calls to the doctor’s service.
- Once the appointment is confirmed, an event can be triggered to send emails to the patient and the doctor via the email service.
- As a result, the patient and the doctor are promptly informed about the newly booked appointment via email.
Yet another design can have the patient receive a response once the appointment has been confirmed. In other words, the email service API request can be triggered asynchronously after the appointment confirmation.
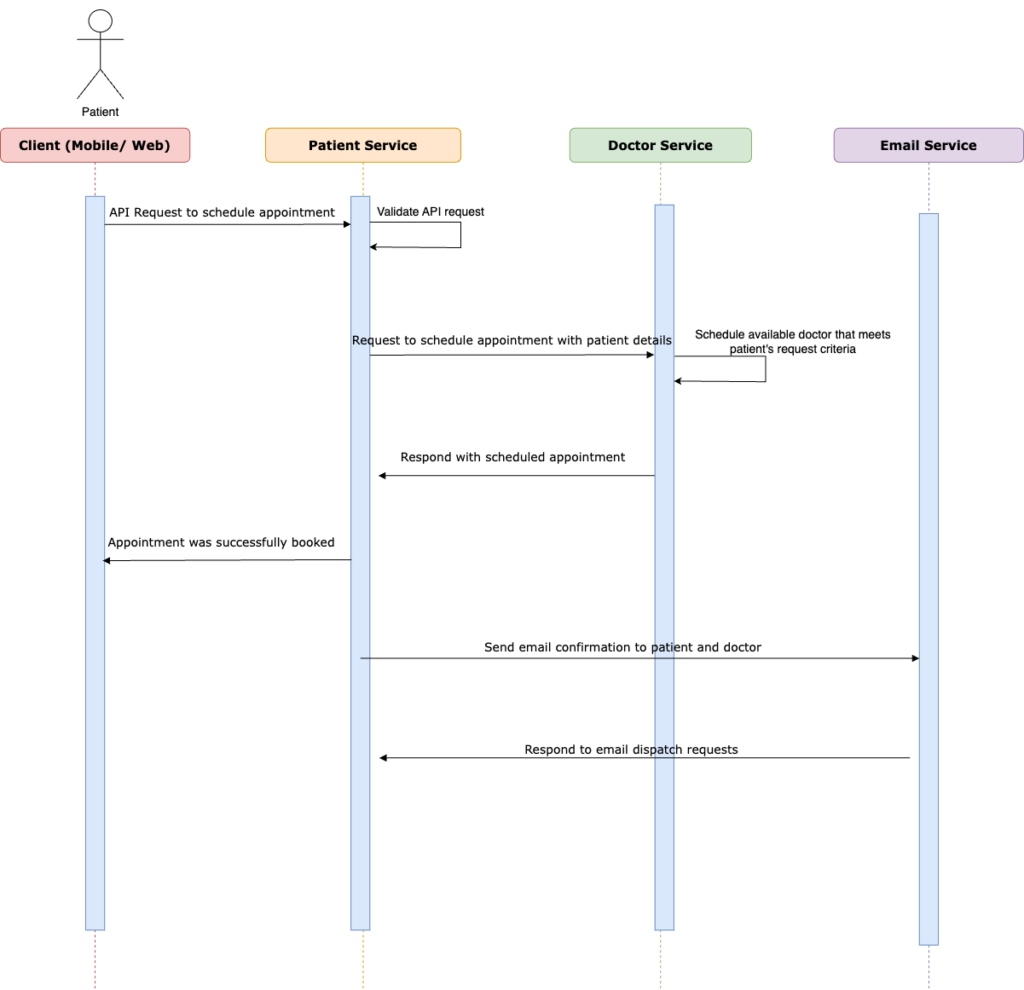
The three approaches provide different user experiences. Hence, the choice to go sync or async relies on the specific use case and user experience we are trying to create.
Distributed Transaction Management
Because we have shifted to a microservices architecture, the task of transaction management has become increasingly complex. In a single database setup, transaction management is fairly straightforward. The typical database management system today ships with inbuild ACID support. However when dealing with multiple databases, we are no longer trying to ensure Data Consistency within a single data source, instead, we are now faced with the challenge of managing DC across multiple data sources.
Remember a transaction comprises a set of operations that must either succeed completely or fail completely. Distributed Transaction Management is the management of transactions that span multiple microservices. In a distributed transaction, all the operations across all transaction participants must succeed completely or fail completely. A number of patterns exist to facilitate the coordination of such transactions.
One such pattern is the SAGA pattern, which seeks to coordinate distributed transactions by combining local transactions from each of the participating services. Each service is responsible for handling its own local transaction, resulting in two types of SAGAs:
- Choreography
- Orchestration
In the case of a Choreography SAGA, each service acts as a peer and must publish a message to the next service in the sequence after completing its local transaction. In the event of a local failure, the service must publish rollback messages to the prior service(s) on the chain. Essentially, every component in the chain must implement an undo function that can reverse the effects of a local transaction. This ensures that all services within the SAGA are in sync, which in turn guarantees data consistency across all data sources.
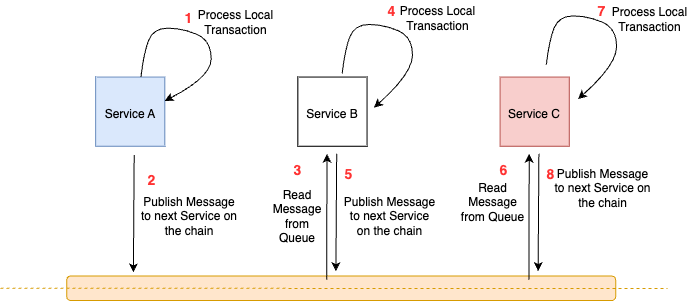
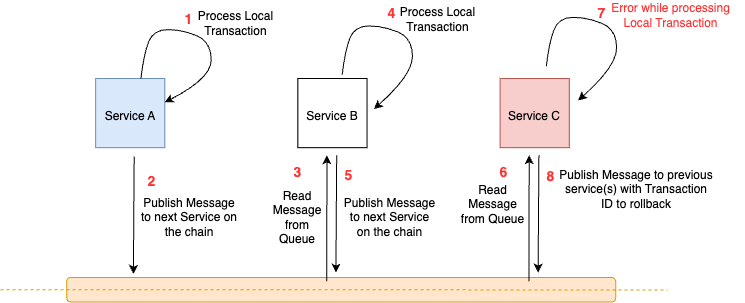
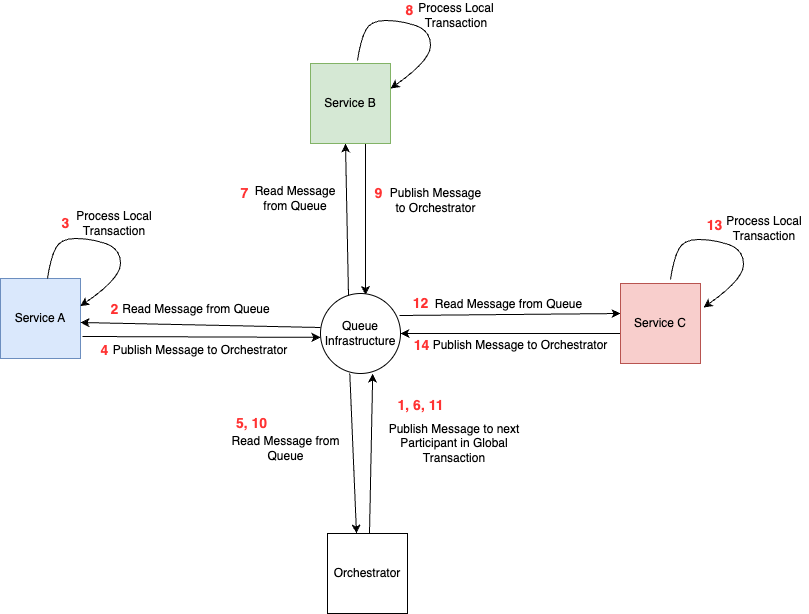
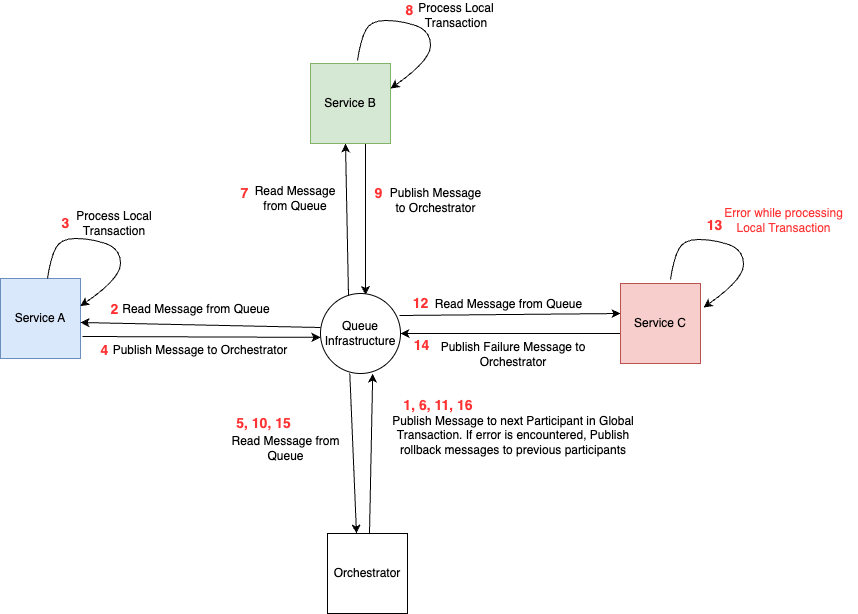
In the case of Orchestration, you have a central coordinator or orchestrator whose primary purpose is to publish messages to each of the services and coordinate the global transaction. If any of the services inform the coordinator of a failed local transaction, the coordinator is responsible for publishing messages to the other services to roll back their local transaction.
Messaging is a very important part of microservice architecture. More often than not, we would like our services to be able to talk to each other. A good principle to adhere to is one of decoupling, where services are able to exchange information without being explicitly aware of each other. Messaging is one way we can decouple our services from each other while allowing them to communicate.
A messaging infrastructure consists of producers and consumers, or publishers and subscribers, or emitters and receivers. You get the idea. The point is, a service produces the message that is transmitted through the infrastructure, and another service that is interested in that message subscribes to it and receives the message in order to process it.
Some well-known message queues: RabbitMQ, Redis, ActiveMQ, Kafka. Queues allow us to establish an underlying mechanism through which services can pass events or messages to each other without explicitly knowing about each other. The less our microservices know about each other, the easier it is to maintain and extend our system.
Another problem starts to arise: how do we reliably publish events to external services? We can explore a few ideas:
- Transactional Outbox
- Database Change Log Tailing
Transactional outbox:
When you implement a database per service pattern, within the context of a service, we may wish to update its local database and afterward publish a message to the queue such that consumer(s) downstream can receive that message and act on it. Updating the local db and message broker is in fact a dual write problem which is a classic problem you face when building distributed systems. How do we reliably update both systems without creating inconsistency in our global state? What happens if one of the updates succeeds and the other fails?
One solution to this problem is the Transactional Outbox Pattern. In this pattern, messages that need to be sent from a service are persisted in an outbox table on the local service database. The outbox table is populated within the local transaction context, leveraging transaction ACIDity. What this means is that all the updates to the local database including the outbox table writes are committed within the same transaction. Once the transaction is committed, all outgoing messages related to the transaction will be logged in the outbox table. The table usually has a schema that includes:
- message_id – the message id should be a unique string.
- message_type – messages of the same type would be logged to the same topic or channel.
- header – optional, but used to include additional information in the message.
- payload – could be a string or a JSON. Ideally, the payload should be self-contained; meaning the downstream services consuming this message should be able to act on the message from the content of the payload.
- timestamp – the time the event happened as captured by the system.
- status – PENDING or DISPATCHED. The status of the message will be persisted as PENDING until it has been dropped in the queue before it moves to DISPATCHED.
After logging messages in the outbox table, the next step is to dispatch events to the message queue. This can be achieved by a scheduler on the application layer that peruses events in PENDING status and pushes them to the queue. Once the event is successfully pushed to the queue, its status is updated to DISPATCHED. However, this process is not entirely foolproof; the update to the DISPATCHED state can fail even after writing to the queue; for example, if your system crashes after you publish a message. As a result, the system will retry pushing the same message to the queue later, which can result in double messages with the same ID.
To mitigate the risk of double messages, it is crucial to have idempotent consumers. These consumers should be able to handle double messages gracefully by inspecting the message ID to know if they have handled the message before. If so, they can ignore the double message. Idempotency ensures that the system can handle double messages without introducing any inconsistencies in the global state.
By leveraging the Transactional Outbox Pattern with idempotent consumers, you can effectively address the dual write problem when building distributed systems using a microservices architecture. These patterns and techniques help to ensure the consistency and reliability of the system, even in the face of failure.
Then there’s Database Change Log Tailing
Another approach to publishing events to a message queue is Transaction Log Tailing. Database vendors typically have a means of logging change events. MySQL has binlog, Postgres has WAL (Write Ahead Log). Every write to the database instance (create, update, delete) gets recorded on the change log. We can tail our change log for specific write events and stream the updates to a queue.
Using a tool like Debezium. We can read change events emitted at the database level on Outbox Message writes and then stream these changes to a message queue. In another article, I plan to show how this can be done in a scalable manner.
Conclusion
While we have explored many aspects of microservices, there is still so much more to discover. As microservices scale from processing a few thousand requests to processing millions of requests daily, new concepts like resilience, fault tolerance, monitoring, observability, security, and release management come into play.
As software engineers, our ultimate goal is to create solutions that delight our users and drive business success. By fully embracing the intricacies of microservices and understanding the trade-offs in our architectural decisions, we can optimize for the best user experience. This unlocks the full potential of the business and paves the way for innovation. So let’s keep pushing the boundaries as we continue to create amazing solutions that deliver value to our users.
Further Reading
- Distributed Transaction: https://en.wikipedia.org/wiki/Distributed_transaction
- Synchronous vs Asynchronous: https://www.mendix.com/blog/asynchronous-vs-synchronous-programming/
- SAGA Pattern: https://microservices.io/patterns/data/saga.html
- Transactional Outbox: https://softwaremill.com/microservices-101/
- Change Data Capture: https://en.wikipedia.org/wiki/Change_data_capture