Change Data Capture (CDC) is a technique used to track and capture changes made in a data source, typically a database, and utilize those changes in various downstream systems or processes. With CDC you’re capturing inserts, updates, and deletes – the classic CRUD operations – and using this information to perform tasks, which could be as simple as updating another database or as complex as triggering entire workflows in an event-driven architecture.
The concept of CDC isn’t particularly new. It has been around since the dawn of databases. In the early days, it was mainly used in data warehousing environments. The goal was to transfer only the changed data instead of reloading the entire dataset from operational databases to data warehouses.
Fast forward to today, in our modern world of real-time analytics, microservices, and distributed systems, the concept of CDC has increased in popularity.
Now, one might ask, “Why should we care about CDC? What makes it so important?” To answer that, let’s imagine this: You’re running a global e-commerce platform. A customer just placed an order. Now you need to update the inventory, trigger a payment process, inform a logistics partner, and maybe even update recommendation engines for other users – all in real-time. How do you do this efficiently without impacting the performance of your transactional systems? CDC can help.
At the heart of most software systems is users manipulating your application state by invoking actions. Some actions are read-only, while some actions involve write operations that result in changes in the application state. These changes could be in the form of a database insert, update or delete.
More often than not, if you’re running a distributed systems architecture, you might want to propagate these changes from one part of the system to another. CDC has this concept of source and target. The source, where the change events originate, is typically a transactional database. The target is where we want these change events to be mirrored or used – could be a data warehouse, another database, or any system that’s hungry for this fresh data.
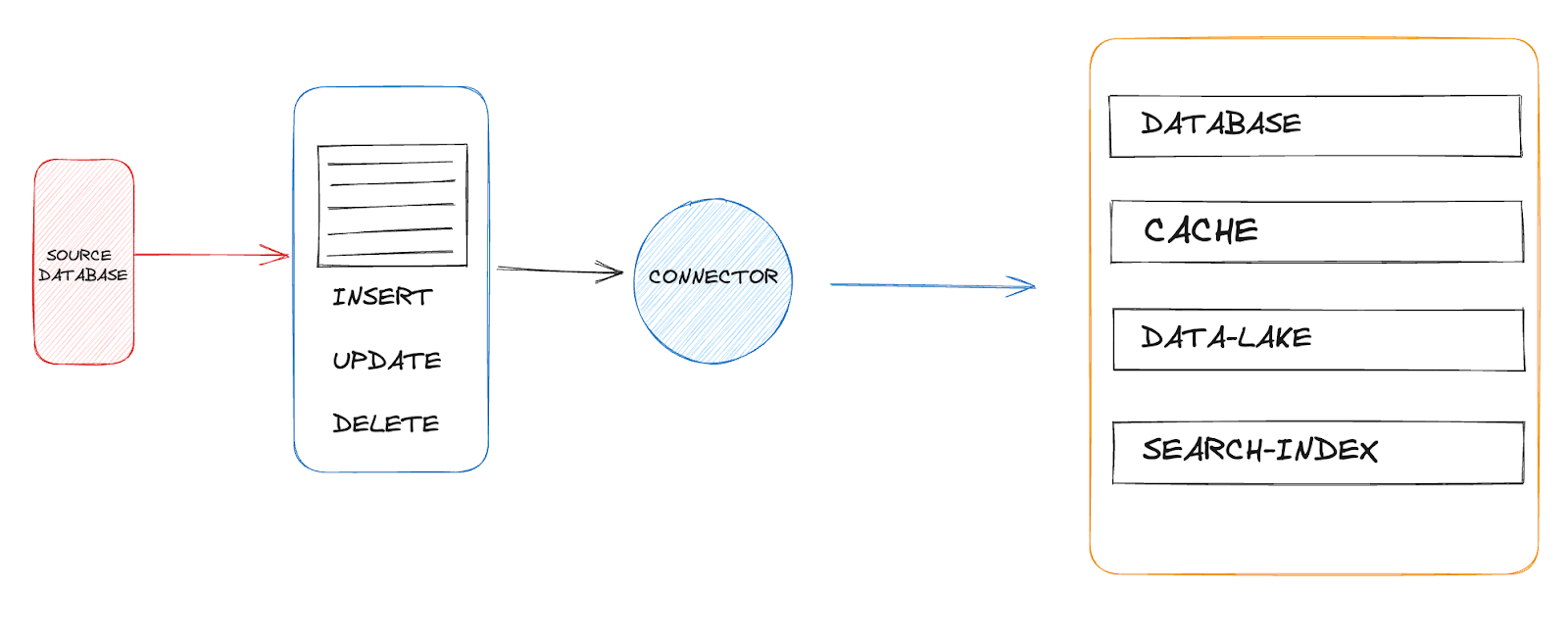
Forms of Change Data Capture
So how do we capture these changes? There are three primary techniques:
- Timestamp-based: This is a pull-based approach where systems query the source based on the last updated timestamp. Source items with the last updated timestamp above the threshold can be read for change updates.
- Trigger-based: This is a push-based approach that can rely on using database events and triggers to propagate change events from a data source.
- Log-based: This is a pull-based approach that involves tailing the changelog file for a data source and looking for specific entries in the logs. The log entries are propagated to downstream systems in real-time.
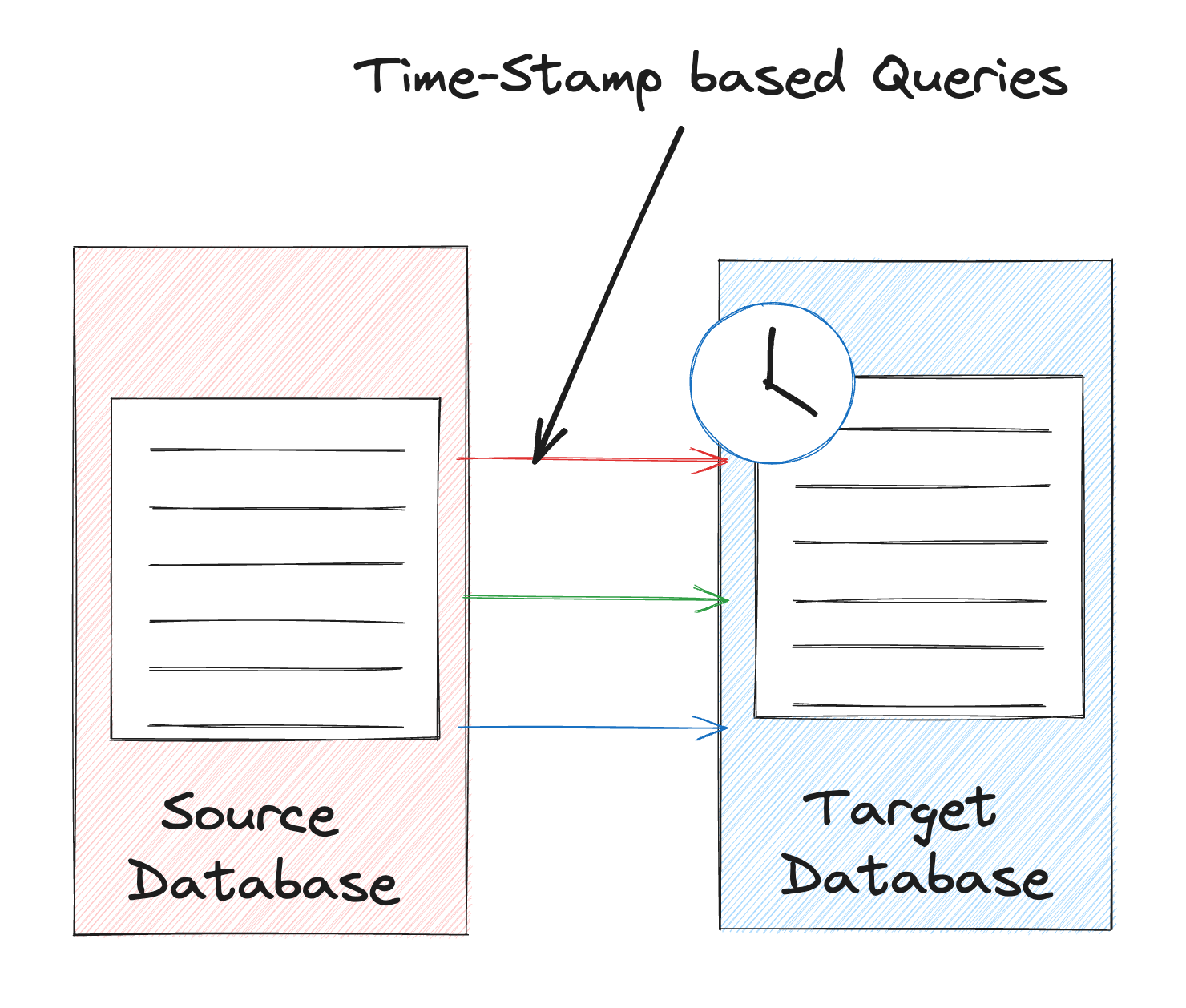
Timestamp-based CDC relies on querying the source at intervals with a timestamp threshold. Changes after the timestamp are loaded into the target.
This approach is my least favorite because the target becomes a burden on the source. Imagine the source is receiving heavy traffic. If the target starts querying the source at intervals, that could add load to the source system.
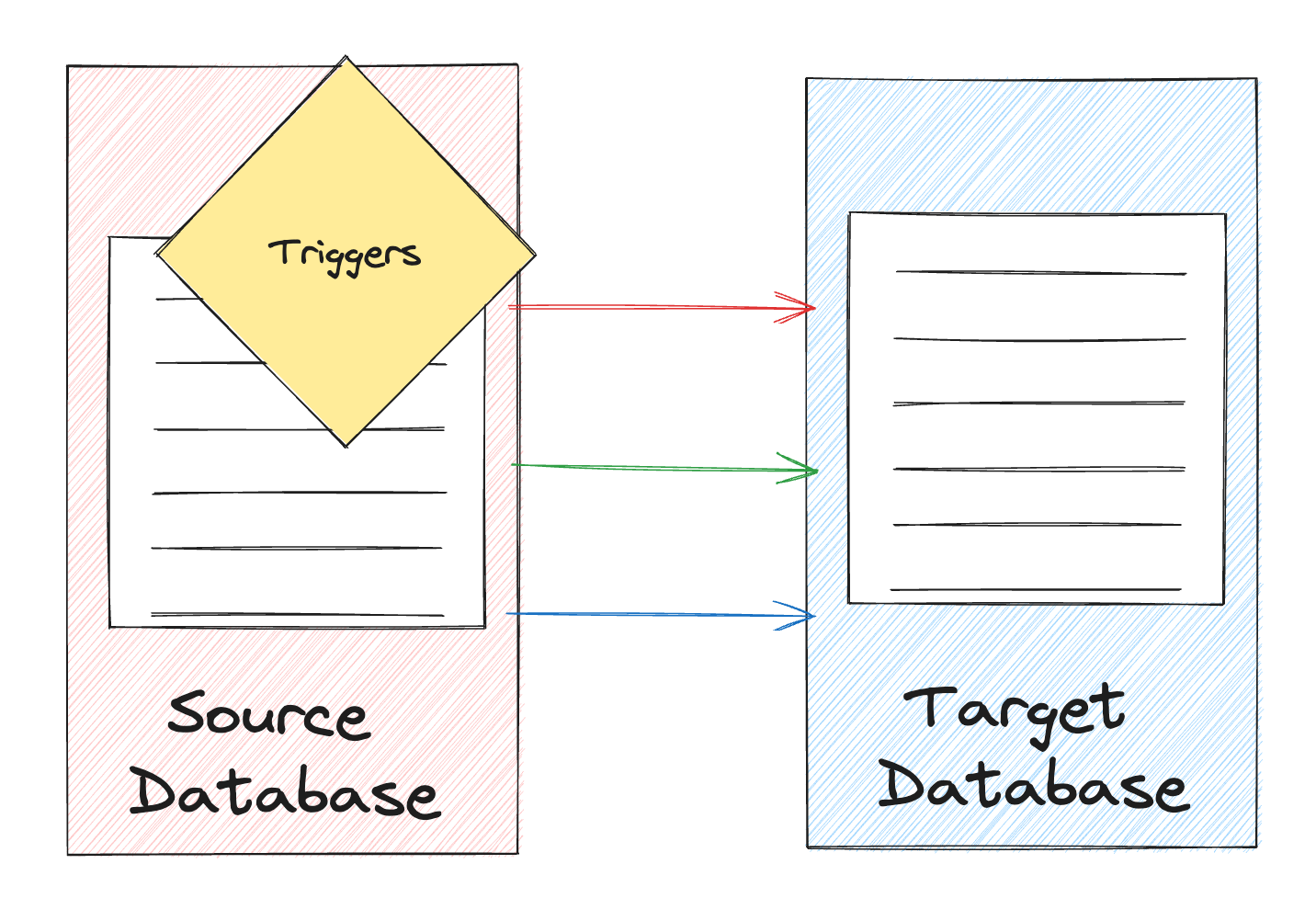
Trigger-based CDC relies on triggers at the source db to push changes to the target. I prefer this to the timestamp-based approach. However, since each change update at the source will require a trigger to be invoked, triggers can add some overhead at the db level. The trigger is a piece of code that could quickly add up in times of high traffic.
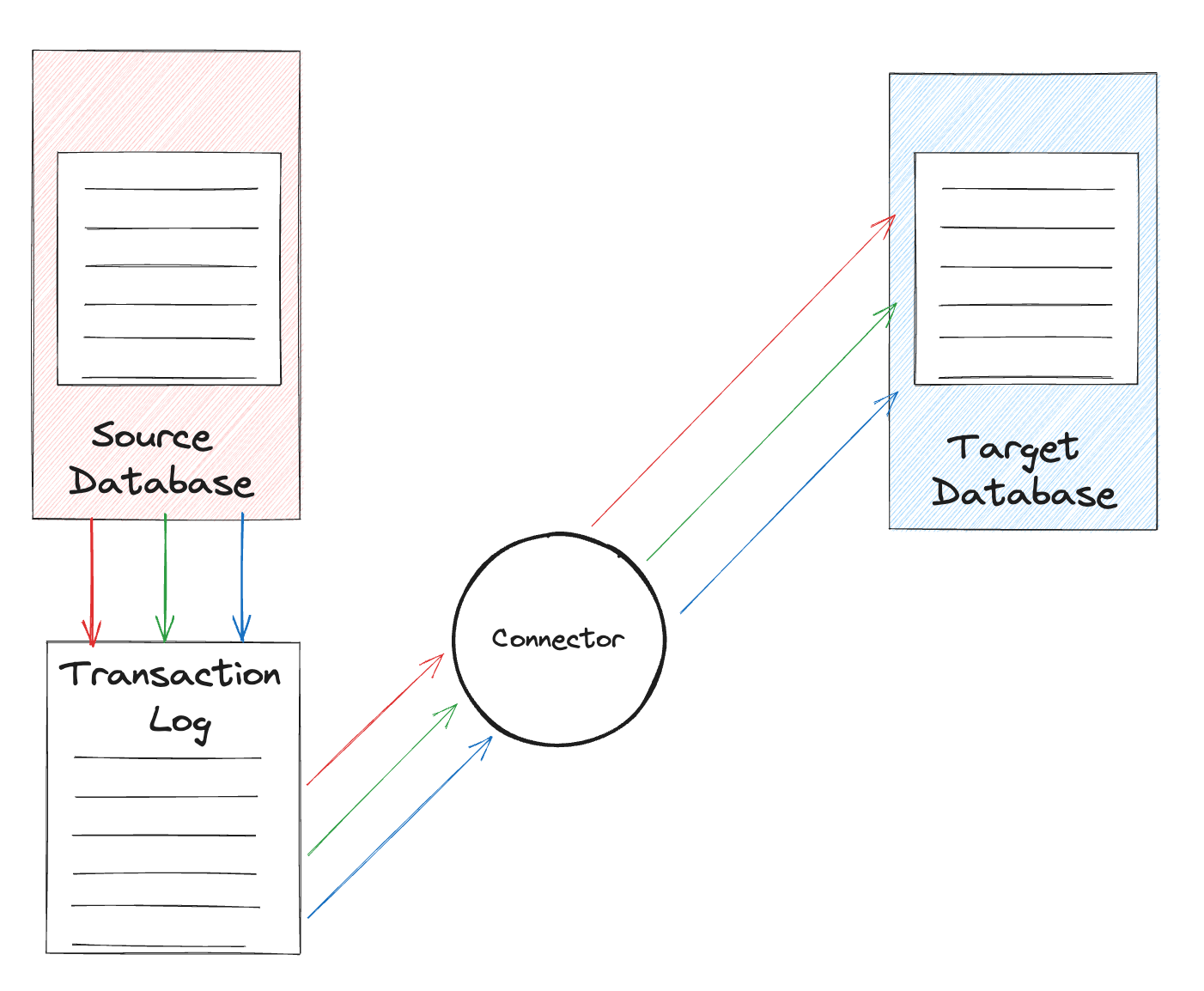
The log-based approach happens to be my favorite of all 3 because it’s the least intrusive. The source database logs changes in the transaction log. Changes are read by a connector and logged to a target. Databases today already have the idea of transaction logging. So adding a connector to the transaction logs is not going to impact the source system in any way.
Real-Life Applications of CDC
- Real-Time Analytics
- Data Replication
- Audit Trails
- Event-Driven Architecture
Let’s look at these real-life examples or applications of CDC in some detail.
We have Real-Time Analytics. Say you’re running an e-commerce business, and you want to provide personalized recommendations to your customers based on their browsing and purchasing history. In such a scenario, you can’t wait for end-of-day batch processing to update your recommendation engine. You’re dealing with real-time data needs. Here’s where CDC can come into play. With CDC, changes to user data can be captured and sent to the recommendation engine in real-time, providing up-to-date personalized experiences to your users.
Another example use case of CDC is Data Replication. In a distributed systems setup, It’s not uncommon to have the same data stored in different places for various purposes. CDC allows you to capture changes from a source database and apply them to a target database, keeping your data fresh and consistent across systems.
Our third application of CDC is Audit Trails. In many industries, knowing who changed what and when is not just good practice; it’s sometimes a legal requirement. I work in financial technology, and many times, we want to know who made certain changes in the system. CDC can capture changes along with the metadata like when the change was made and by whom, allowing you to keep a complete audit trail.
Finally, CDC can be applied to Event-Driven Architectures. This is where CDC truly shines! In an event-driven system, actions or ‘events’ in one part of the system trigger actions in another part of the system. CDC can capture data changes as events, triggering downstream processes like workflows or notifications.
Deep dive into a log-based CDC tool (Debezium)
Much of my experience with Change Data Capture has been with the popular tool called Debezium. From the official website, Debezium is described as an open-source distributed platform for change data capture. When pointed at your data source, it can help you respond to inserts, updates and deletes in a fast and durable manner. Let’s look a bit closer at how Debezium works:
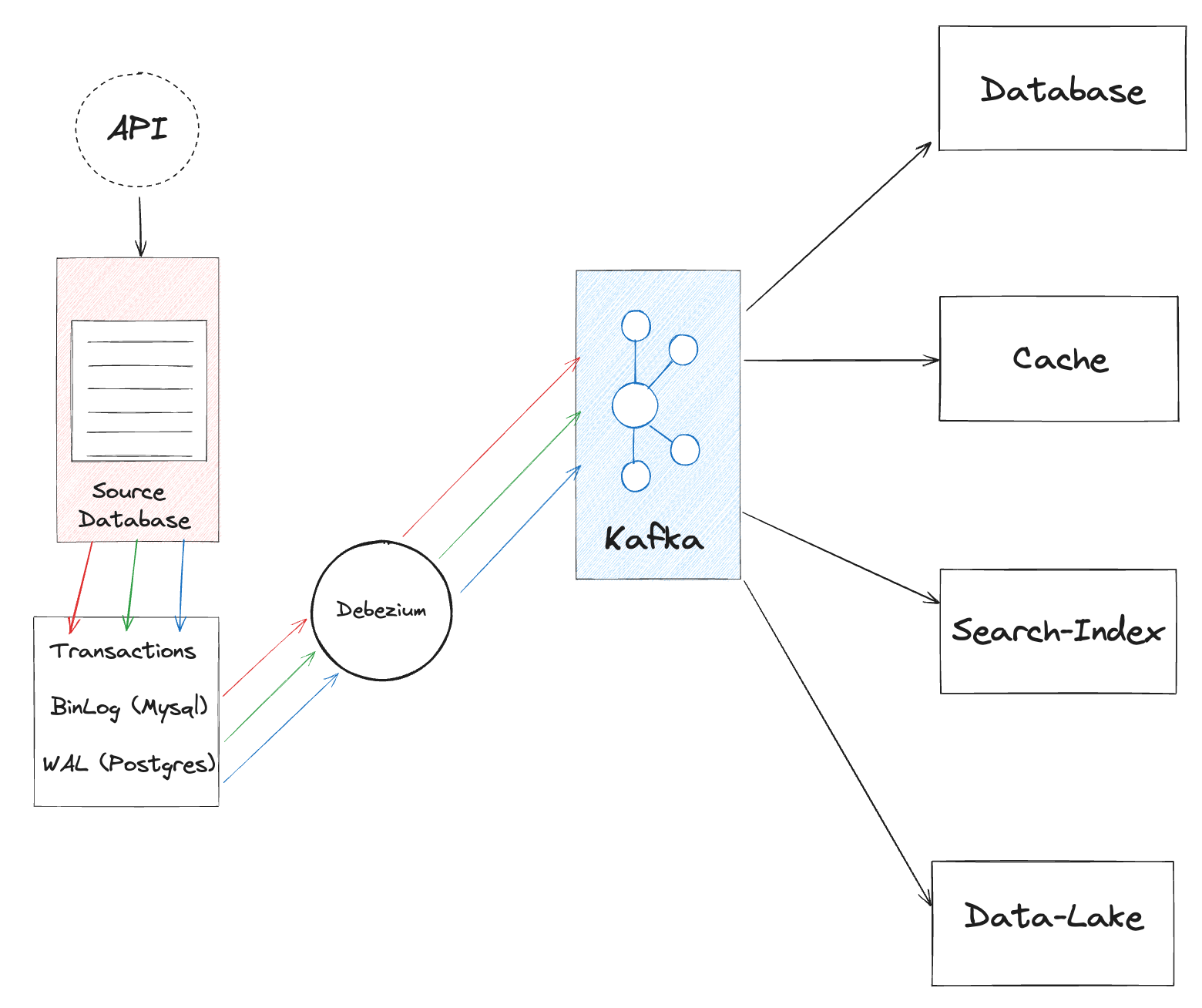
By pointing Debezium at your data source, it is able to stream change updates (inserts, updates, and deletes) into a messaging queue like Kafka. Thus facilitating real-time data pipelines and streaming applications. Consumers can then plug into Kafka and utilize the streamed updates however they please.
Aside from streaming change updates, Debezium also accounts for schema evolution. The database schema changes are also included in the updates to Kafka, allowing downstream clients to keep track of the shape of the data as they process it.
After Debezium streams data source changes to Kafka, different kinds of services can connect to Kafka and process the change updates. In the diagram above, we have a data source, cache, search-indexer, and data lake all connected to kafka to process the streamed change updates from debezium.
Setup
To run a basic setup for debezium with MySQL, one can follow the official documentation here:
https://debezium.io/documentation/reference/2.3/tutorial.html
The documentation shows how you can plug a connector to a MySQL instance and start reading change events from the MySQL database. Instructions are straightforward and easy to follow. One should be able to complete the setup and testing in under an hour or two.
CDC connector lib
Over the past few months, I built a library that allows one to easily set up connectors to a data source and read change events. The library allows for two primary CDC use cases: Change Replication and Change Processing. Here’s the source code for the library:
https://github.com/durutheguru/cdc-connector-lib
For the rest of this write-up, I’ll work with the library to demonstrate some things that can be accomplished with Change Data Capture.
Let’s run a setup on our local environment to have a fair picture of how this works and how we can utilize it. We’ll make use of the docker-compose file in the project resources folder:
version: '3.1'
services:
zookeeper:
image: wurstmeister/zookeeper
ports:
- "2181:2181"
networks:
- docker-net
kafka:
image: wurstmeister/kafka:latest
depends_on:
- zookeeper
ports:
- "9092:9092"
- "9093:9093"
environment:
KAFKA_ADVERTISED_HOST_NAME: kafka
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
KAFKA_LISTENERS: PLAINTEXT://:9092,PLAINTEXT_HOST://:9093
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka:9092,PLAINTEXT_HOST://localhost:9093
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
networks:
- docker-net
akhq:
image: tchiotludo/akhq
environment:
AKHQ_CONFIGURATION: |
akhq:
connections:
docker-kafka-server:
properties:
bootstrap.servers: "kafka:9092"
connect:
- name: "connect"
url: "http://connect:8083"
ports:
- "8181:8080"
networks:
- docker-net
mysqldb:
image: mysql:8.0
restart: always
healthcheck:
test: "mysql $$MYSQL_DATABASE -uroot -p$$MYSQL_ROOT_PASSWORD -e 'SELECT 1;'"
interval: 10s
timeout: 300s
retries: 20
environment:
- MYSQL_DATABASE=employee
- MYSQL_ROOT_PASSWORD=1234567890
ports:
- "33080:3306"
volumes:
- db:/var/lib/mysql
networks:
- docker-net
postgres:
image: postgres:latest
ports:
- "5432:5432"
environment:
- POSTGRES_PASSWORD=password
- POSTGRES_USER=postgres
- POSTGRES_DB=employee_database_sink
networks:
- docker-net
connect:
image: quay.io/debezium/connect:2.2
restart: always
depends_on:
- kafka
ports:
- "8083:8083"
- "5005:5005"
links:
- kafka
- mysqldb
environment:
- BOOTSTRAP_SERVERS=kafka:9092
- GROUP_ID=1
- CONFIG_STORAGE_TOPIC=connect_configs
- OFFSET_STORAGE_TOPIC=connect_offsets
- STATUS_STORAGE_TOPIC=source_connect_statuses
networks:
- docker-net
volumes:
db:
networks:
docker-net:
The file consists of the following services:
- Zookeeper: For distributed consensus, orchestration, and cluster management of our Kafka broker(s).
- Kafka: Our messaging queue, where change updates will be streamed.
- AKHQ: A viewer for our Kafka instance. Akhq allows us to view topics, connectors, and messages in Kafka
- Mysql: The database from where we intend to stream our change updates. Debezium will connect to this MySQL instance and stream change updates to Kafka.
- Postgres: The destination database for our replication events. Data that is read from MySQL will be replicated to Postgres in our setup.
- Debezium: The debezium connector will do the heavy lifting of connecting to the Mysql log and updating kafka based on changes in MySQL db.
Look for DatabaseSyncTest in the package com.julianduru.cdc.examples. Because we want to look at the changes happening in our CDC pipeline, we will enable inspection on the test. Modify the environment variables on the test configuration and set INSPECTION_ENABLED=true.
Next, inspect the application.yml file in the test resources folder. The part showing the configuration we’re primarily interested in:
code.config.connector:
url: http://localhost:8083
source-connectors:
- name: cdc_connector
connectorType: MYSQL_SOURCE
databaseHost: mysqldb
databasePort: 3306
databaseUsername: root
databasePassword: 1234567890
databaseIncludeList:
- employee
tableIncludeList:
- employee.user
kafkaBootstrapServers:
- kafka:9092
sink-connectors:
- name: sink_connector
connectorType: JDBC_SINK
topics: cdc_connector.employee.user
url: "jdbc:postgresql://postgres:5432/employee_database_sink"
username: postgres
password: password
The configuration above has source and sink connectors. The source connector points to MySQL DB, and the sink connector points to the Postgres DB.
When the test is run, it will hang because inspection has been enabled. This will allow us to look at our Kafka cluster and slowly inspect what is going on when we CDC.
In the test resources, you’ll notice the schema.sql and data.sql files which provide some data to be loaded into our MySQL instance.
USE `employee`;
CREATE TABLE user (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(50) NOT NULL,
address VARCHAR(100),
gender ENUM('M', 'F')
);
schema.sql
USE `employee`;
INSERT INTO `user`(`name`, address, gender) VALUES('Julian Duru', '7th House, Main Street', 'M');
data.sql
Connect to the database instances using a client like DBeaver. MySQL should be available on localhost:33080. Postgres should be available on localhost:5432. Exploring the user table in the employee database in MySQL, you should have a single entry in the table. The same entry should exist in the Postgres table called cdc_connector_employee_user.
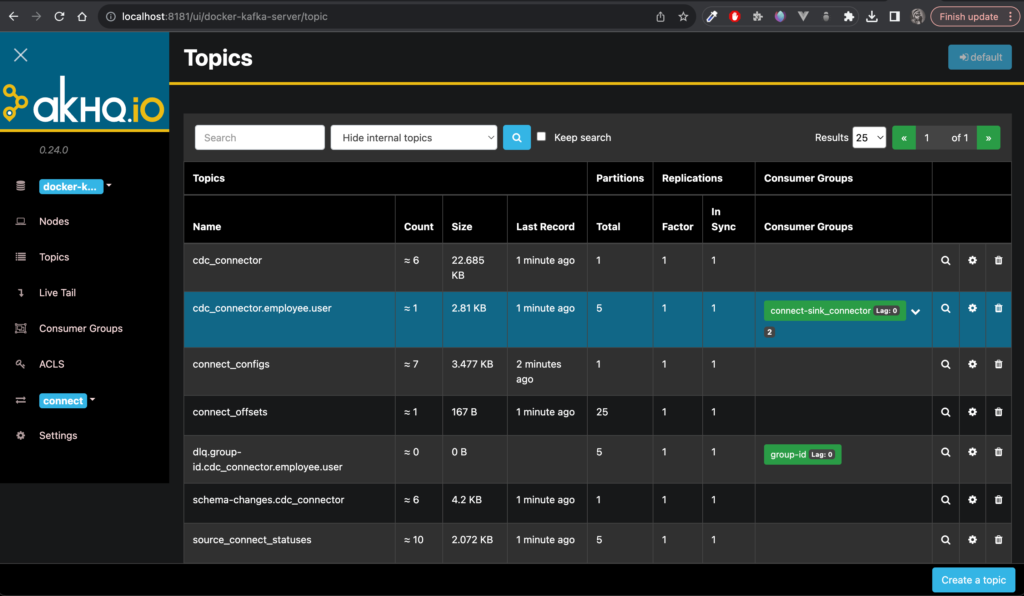
Changes made to the MySQL table are replicated on the Postgres table instantly. Let’s take a closer look at the magic going on here. For that, we’ll look at AKHQ.
AKHQ serves as a viewer into our Kafka cluster; allowing us to inspect topics and messages. If you inspect the source connector configuration in application.yml, for each source table, the connector lib will create a topic with the format: {{connector_name}}.{{database_name}}.{{table_name}}. Hence, we should have a topic called cdc_connector.employee.user. Inspecting the topic, you should see all the messages containing change logs on the MySQL database table called user.
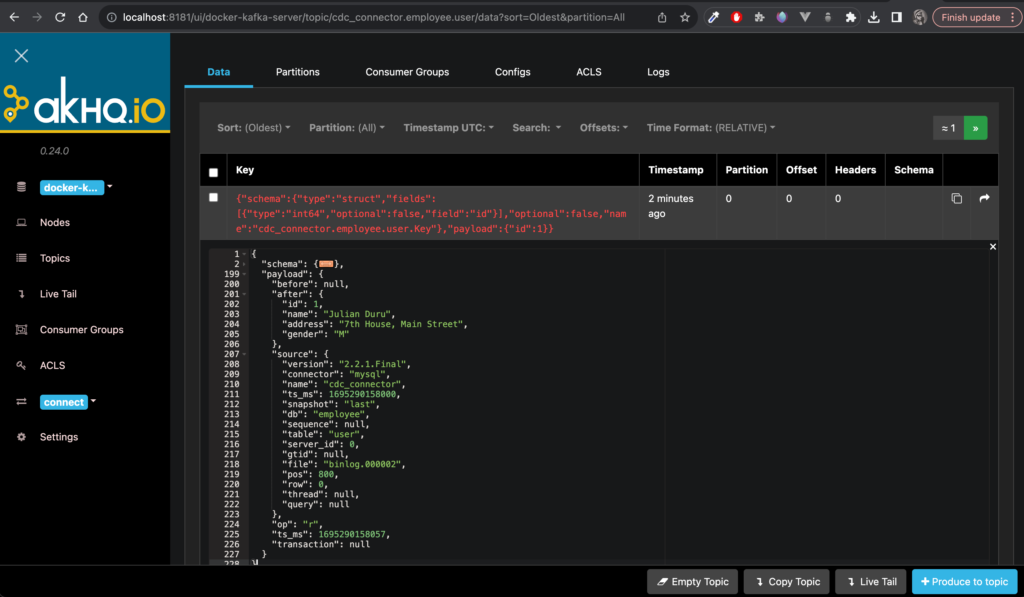
The messages contain a schema part and a payload part. The schema contains the data about the payload that will assist in replication to the sink. The payload contains the data of the change that happened in the table. The payload consists of the following parts:
- before: What the data looked like before the change happened. In the case of a create event, before will have a null value.
- after: What the data looked like after the change happened. In the case of a delete event, the after will have a null value.
- source: The source of the change update. This typically includes the database name, table name, binlog offset, and other relevant information.
- op: The operation that was carried out. Will usually contain a single character. ‘c’ for create, ‘d’ for delete, ‘u’ for update, ‘r’ for read.
- timestamp: The timestamp when the change happened. This value will be in milliseconds.
As you make changes to the MySQL database, the changes will be written to the Kafka topic: cdc_connector.employee.user. From there, the changes are replicated in the Postgres sink.
So far, we have covered change replication with the cdc-connector-lib; now let’s look at change processing.
For that, we can look at 2 classes: CreateUserChangeProcessor, and UpdateUserChangeProcessor. Both in package com.julianduru.cdc.changeconsumer. The CreateUserChangeProcessor has the following structure:
@Slf4j
@RequiredArgsConstructor
@ChangeConsumer(sourceId = "employee.user", changeType = ChangeType.CREATE)
public class CreateUserChangeProcessor {
private final DataCaptureMap dataCaptureMap;
public OperationStatus process(String reference, Payload payload) {
log.info("Payload: {}", JSONUtil.asJsonString(payload, ""));
dataCaptureMap.put(reference, payload);
return OperationStatus.success();
}
}
If you notice the @ChangeConsumer annotation, you’ll see that the processor is meant to handle change updates when a user is CREATED on the employee db. Hence, when a new user is CREATED, the processor’s process method will be invoked with the Payload. The reference will usually be a hash of the Payload.
The processor is now free to process the change update however they wish and then return an OperationStatus at the end. If the processor returns a final state, then it won’t be called again. However, if the processor returns a non-final state, it will be invoked until it returns a final state.
The payload object mirrors the payload we see in our Kafka topics, hence our payload will have before, after, source, op and timestamp sections.
What about the Update Processor?
@Slf4j
@RequiredArgsConstructor
@ChangeConsumer(sourceId = "employee.user", changeType = ChangeType.UPDATE)
public class UpdateUserChangeProcessor {
private final AtomicInteger failureCount = new AtomicInteger(0);
private final DataCaptureMap dataCaptureMap;
public OperationStatus process(String reference, Payload payload) {
log.info("Payload: {}", JSONUtil.asJsonString(payload, ""));
if (failureCount.getAndIncrement() < 3) {
return OperationStatus.failure();
}
else {
dataCaptureMap.put(reference, payload);
failureCount.set(0);
return OperationStatus.success();
}
}
}
The Update Processor is invoked when a user entry in the employee database is updated. The difference in the payload now is both before and after sections contain objects that include the state of the row entry before and after the change was made.
Looking at the logic of the update processor, it returns a failure 3 times before returning a success. Hence if you make a change to an existing row entry in the MySQL database, the update processor will be invoked 3 times before it clears processing.
When not to use CDC
CDC is a delightful technique to use when attempting to capture change events at a source and utilize those events in downstream systems. However, there are some instances when it’s not appropriate to use CDC:
- If tracking every data change is overkill. Sometimes you don’t need the overhead of tracking each change to your data. There are other simpler techniques that would suffice.
- Limited Budget: be mindful of the Kafka bill. Each database change results in a write to Kafka; if you’re using a cloud-managed Kafka instance, your Kafka bill can blow up very quickly. So be mindful.
- Risk of exposing sensitive information: In some cases, you don’t want to expose sensitive information from your database to other clients. You want to keep data changes isolated within your respective sub-domains.
- Workload is more Read-Heavy than Write-Heavy: If your application does a lot more reading than writing, it might not be appropriate to use change data capture.
In Conclusion,
We have gained a gentle introduction to Change Data Capture as a concept. Even looked at how we can do a setup using Debezium. I also introduced a library I built which includes an engine for integrating debezium connectors with different data sources. We also looked at how this library can be applied to Change replication and Change processing. Finally, we looked at when it’s not appropriate to use Change Data Capture.
All in all, CDC is a wonderful technique that can solve technical challenges when used appropriately. We should apply this technique with the drawbacks in mind, knowing that architecture is about choosing the best solution among competing alternatives, and each solution has its pros and cons.