Machine Learning is a subset of Artificial Intelligence that applies mathematical models and statistical methods to teach computers to make decisions towards achieving a goal.
The term ‘Artificial Intelligence’ (or AI for short) is used to indicate some resemblance to human intelligence being exhibited by computers or machines. AI systems exhibit behaviour that mimics human cognitive functions. By cognitive functions, i mean tasks related to learning, acquiring knowledge, and utilising acquired knowledge to make decisions. Examples of machine learning applications are email spam filtering, facial recognition, speech to text, recommendation systems, the list goes on.
In light of recent advancements in technology, it has become apparent the rate at which we churn out and process data will only increase for the foreseeable future. Currently, humans generate roughly 2-3 quintillion bytes of data everyday. This in itself is a testament to the success of the internet. More-so, we have transitioned into an era where data is considered high value. I guess it’s because data is a reflection of reality and by studying this reflection we can extract meaningful insights and do even bigger things.
The human mind, while a fascinating work of nature capable of demonstrating unlimited potential for creativity, is still very limited in terms of its processing capacity. I’m referring to the total amount of information our minds can hold and process. To address this limitation, we rely on computers to augment our capabilities. This opens up a new class of problems to enable machines mimic human intelligence; a class of problems that cannot be solved by coding explicit instructions, but rather applying algorithms that can ’teach’ a machine to learn from its surroundings and make informed decisions by itself. That, is what machine learning is all about.
Machine Learning algorithms are classified into 3 broad areas:
- Supervised Learning
- Unsupervised Learning
- Reinforcement Learning
Supervised Learning
In mathematics, we define a function F as an operation that can accept one or more input parameters and return an output. Something like this:
F(X) = Y
Meaning when X is supplied, we can carry out an operation F on X and the result is Y.
In Supervised Learning, we seek to derive a function F that can map any X input to its corresponding output Y. We do not know what this function is, but we intend to ‘learn’ this function based on examples of X inputs and corresponding Y outputs which we already know. These examples are called training data. The process of using training data to figure out F is called fitting.
Supervised learning, as the name implies is a form of machine learning that happens in the presence of outside intervention or supervision. The outsider in this case is a teacher of some sort whose role is to prepare and introduce the training examples.
How Supervised Learning generally works.
Since this post is merely a primer on machine learning algorithms, i will avoid going too deep. Here’s what I know:
Supervised Learning algorithms utilise a cost function while estimating the suitability of a model. Think of a cost function as a function that outputs a value denoting some cost incurred by using our function F as is. The cost is an indication of the difference between our function (F) output and the expected output. So, we can assume the cost is higher as F outputs move farther from our expectations.
The goal is to minimize our cost function. That is, arrive at an F whose output values coincide with or are very close to our expectations. There are a lot of other technicalities involved, which I should dive into in other posts. For example, while fitting your model on the training data, you need to avoid over-fitting your model or ‘memorizing’ the training data. What this creates is a scenario where your model correctly predicts values encountered in training, but fails when introduced to new data.
Supervised Learning algorithms vary in form and the context in which they are applied. The most basic example of supervised learning is Simple Linear Regression. SLR tries to identify a target function of the form y = mx + b, that is, a straight line function with x as the independent variable, and y the dependent variable.
Using training examples containing already known (x, y) pairs, we arrive at the function that best fits the training data and is able to generalize on new data. Multiple Linear Regression goes a step further from SLR with more than one independent variable, resulting in a more complex, non-linear target function. Other Subclasses of Supervised Learning algorithms: Logistic Regression, Naive Bayes, K-Nearest Neighbours, Linear Discriminant Analysis, etc..
Spam Filtering is a good application of supervised learning. We utilize a training set of spam and non-spam emails that we label and feed into our algorithm. In the process, we learn a model for classifying spam from non-spam email and can apply that model to real emails.
In future posts I will dive into some of these algorithms… but hopefully you already get the idea.
Unsupervised Learning
Unsupervised learning takes a different approach that does not rely on providing training examples, but instead allowing our model to discover patterns in data by itself.
Unsupervised learning is usually deployed in real-time scenarios. That is, learning relationships as we encounter new data while evolving in real-time. Based on these relationships, informed actions can be taken. The opposite is the case in supervised learning algorithms where training data is already known and provided by a ’teacher’.
Most applications of unsupervised learning are restricted to association and clustering problems.
Clustering is perhaps the most widely used application of unsupervised learning because a lot of data is largely unstructured. Think of a cluster as a group of objects that have similar features. Clustering helps identify patterns in data in order to segment datasets with shared attributes. Example applications of clustering:
- In earthquake study, clustering can group regions with similar activity and help identify hot-spots or epicentres.
- In market analysis, clustering can help identify groups of customers with similar behaviour.
Another application of unsupervised learning is in Density Estimation, or evaluating how a dataset is spread or distributed within a defined space.
Reinforcement Learning
Reinforcement Learning is an aspect of Machine Learning that involves deploying agents that can learn from experience and make optimal decisions directed towards achieving a goal. These agents depend on a kind of feedback loop in order to evaluate actions and determine whether or not they are progressing towards the goal.
Positive feedback implies a good decision was made and negative feedback implies the opposite. So we can assume that positive and negative feedback are integral to the process of reinforcement learning. All feedback counts as experience which the agent utilizes as it attempts to maximize a net positive reward accumulated over the course of execution.
There are two primary forms of reinforcement:
Positive reinforcement achieved when an agent carries out an action with positive feedback, the agent becomes more likely to repeat such actions in the future.
Negative reinforcement achieved when an agent carries out an action to avoid negative feedback, the agent will be more likely to carry out similar actions in the future.
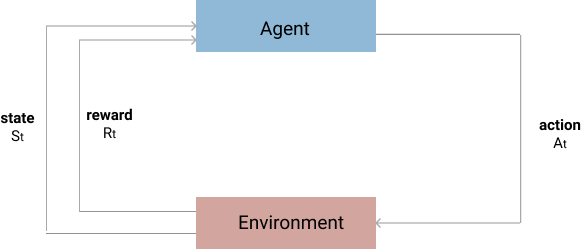
A simple example of reinforcement learning. Assume we have a robot named Alex who is placed in a maze and is tasked with finding a treasure chest.
We can’t explicitly instruct Alex on how to find this treasure chest, but we can define some rules which Alex can follow and learn from. For example,
- If Alex advances in a direction and encounters a terrible monster, that’s negative feedback.
- If Alex advances in a direction that results in a dead-end and requires backtracking, that’s negative feedback.
Alex will try different paths, mostly through trial and error, but taking into account everything he already knows. Over time, Alex will learn the optimal path that will maximize cumulative feedback.
Reinforcement Learning is best suited for making decisions in complex environments. It has many different applications, for example, it has been applied in Resource Management, to enable learning optimal schedules for allocating resources to jobs in order to minimize job lag. RL has also been applied in mastering games with complex outcomes like Go, and Chess.
Machine Learning is really deep. Trust me, the rabbit hole goes deeper and deeper. I merely stayed on the surface in this post. Personally, I would advise anyone to take the project-based approach to learn ML. That is, focus more on building actual stuff and less on learning complex math. That way you don’t get lost in the complexity. In subsequent posts, I will focus more on the practical side of Machine Learning and less on the theory. Bear in mind though, we cannot escape the theory because the theory is what makes the application possible, and a deeper understanding of the principles will help us write even better applications.